




Even after being a software developer, Git still confuses me!
For any developer having knowledge of version control is essential.
Most common in today’s world is Git, invented by Linus Torvalds. Students are rarely taught in schools/universities about version control like Git in their curriculum. However, the tech industry is highly dependent on Git. So, without the knowledge of Git, if a student lands his/her first internship/job, it is challenging to understand how the enterprise works without any prior understanding of Git.
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/12000/0*pmIWN-Kbb7MbPWmL)
So, before we understand the basics of Git, let’s take a glance back at the history of version control.
Over the years, various developers have built some sort of version control system to track their changes. The first of these is called SCCS, for Source Code Control System. It was released in 1972 and was developed by AT&T, and it was bundled free with the Unix operating system. It stored the original version and set of changes. It just saves a snapshot of what the differences were. So if you want version five of a document, you just take version one and apply four sets of changes to it to get to version five. That’s a much more efficient way to store the changes over time. So SCCS stayed dominant until the early 80s, when RCS was developed, Revision Control System. And it just made lots of improvements over SCCS.
With the rise of the personal computer, it was essential to have a version control system that would also work on PCs. Then Concurrent Versions System was developed.
The idea of working with remote repositories was further improved upon with Apache Subversion or SVN. SVN was faster than CVS and allowed the saving of non-text files, like images, where CVS couldn’t do that.
Now CVN has stayed the most popular version control system for a very long time. In fact, until Git came out. But there’s one other version control system that comes in between, and that’s Bit Keeper SCM. It was a closed source, proprietary source code management tool. When Bit Keeper stopped being free, Linus wrote a new version control system, and it was Git.
Now, let’s understand the Git concepts.
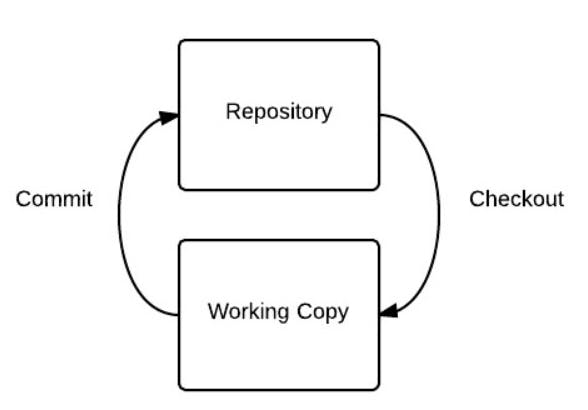 Typical VCS has 2-tree architecture
Typical VCS has 2-tree architecture
Git uses three tree architecture; it has the repository, working copy, and in between another tree, staging index. Working directory, which contains changes that may not be tracked by Git yet, there’s the staging index, which includes changes that we’re about to commit into the repository, and then there’s the repository, and that’s what’s actually being tracked by Git. The changes that Git has and that it’s going to hold onto and keep track of.
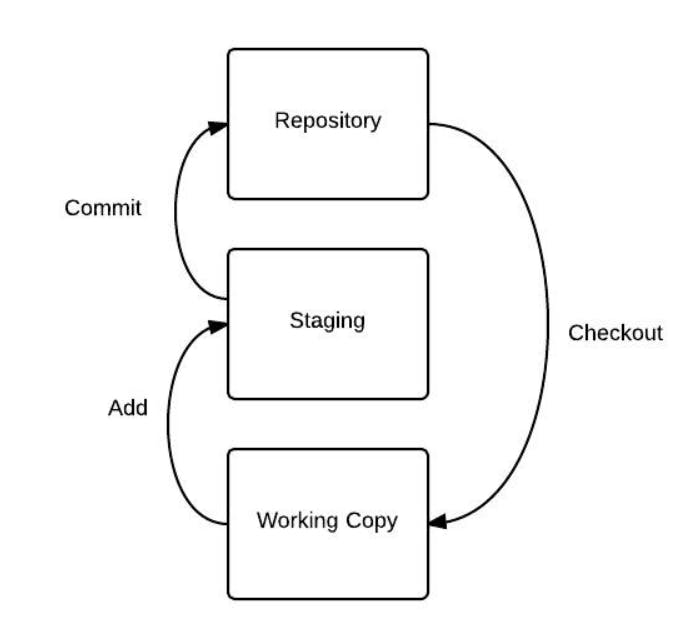 Git uses three tree architecture
Git uses three tree architecture
Key Terminology:
REPOSITORY: It is a local storage on the machine where the project’s entire snapshot is stored.
STAGING/INDEX: It gives a quick preview of the project snapshot that is about to commit.
COMMIT: It is the latest snapshot (state) of a project.
HEAD: It is the snapshot of the latest commit on every branch.
Master: main default local branch when the project is first created in Git.
Branch: It is a parallel, independent line of development. It lets you work on the same piece of code in your isolated workspace.
There are various blogs and cheat sheet out there to help with the basics of Git; one of my favorites is https://education.github.com/git-cheat-sheet-education.pdf
Now, let’s understand various commands of Git, with an example.
Before anything, make sure you have installed Git in your system
Consider an example, you have a project containing 2 files. Now, we need to initialize your project to Git (.git directory is the one that tracks your changes)

As we understood about the three tree architecture, any project changes need to be added to the staging. The Staging area displays a preview of what is going to be committed next.
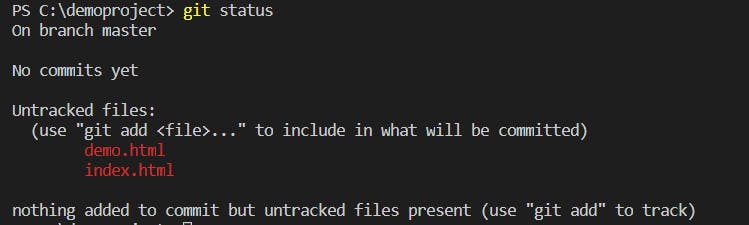 git-status — Show the working tree status
git-status — Show the working tree status
 git-add — Add file contents to the index. It adds both files to staging
git-add — Add file contents to the index. It adds both files to staging
Once we got every file in the staging index. We only need to commit it to push them inside the repository tree
git-commit — Record changes to the repository: The new commit is a direct child of HEAD, usually the current branch’s tip, and the branch is updated to point to it.
C:\demoproject> git commit -m “First Commit towards learning git”
 The unique commit ID is called a ‘git hash’ . Every change (add, delete, edit, move, copy, rename, file permissions, etc.) is treated as a file and its contents are converted into a unique SHA.
The unique commit ID is called a ‘git hash’ . Every change (add, delete, edit, move, copy, rename, file permissions, etc.) is treated as a file and its contents are converted into a unique SHA.
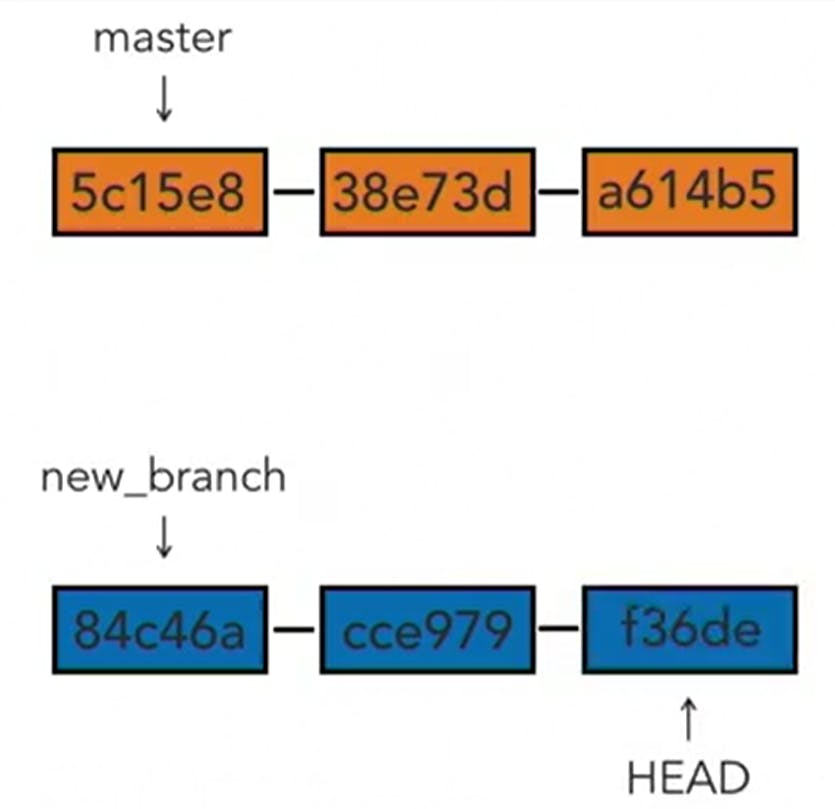
HEAD is Git refers to the latest commit. You can check all the commits made to a project through git log, which generates the commit with the hash value, which can be used to view previous commits or even compare commits by showing the change sets.
Once you get the basic understanding, you can create branches and commit your changes.
It is best practice to have atomic commits, which affect only a single aspect of the code changes, as it’s easier to understand and find bugs and improve collaborations.
I hope you got a better knowledge of Git now!
git commit -m “Keep Learning”
Resources:
Do the read the official documentations at https://git-scm.com/docs Installation: For windows: https://windows.github.com For Mac: https://mac.github.com